在今天的数字时代,文件管理往往会变得令人望而生畏。但是,如果有一种工具可以简化这个过程,使其高效而轻松呢?
欢迎来到ChatGPT代码解释器的世界——您处理文档的终极盟友。无论是批处理文档、给PDF文件添加水印、合并和拆分文件、还是保护内容的密码,这个多功能工具将您的生产力提升到一个全新的水平。
本文揭示了代码解释器提供的无限可能性,使文档管理变得轻而易举。
让我们深入探索其令人惊叹的功能。
-
- 批量给PDF文件添加水印
- 合并和拆分PDF文件
- 从PDF中提取表格和图片
文档非常重要 如果你想显著提高生产力,你可以同时压缩多个文档,然后将压缩包上传到Code Interpreter进行批处理。
批量给PDF文件添加水印 #
给PDF文件添加水印是常见的操作,尤其在专业和商业环境中。许多组织,包括公司、教育机构、政府机构和内容创作者,选择给PDF文件添加水印来保护其内容,彰显所有权并维护品牌形象。
使用Code Interpreter,你可以使用简单的提示来批量给PDF文件添加水印。
请在提供的ZIP文件中的每个页面中心添加一个对角线水印。水印应缩放到目标页面大小的75%。水印的内容应为Courier-Bold字体,灰色,不透明度为50%的"myaiforce.com"。任务完成后, 请分享一个下载链接以获取所有处理过的PDF文件。
为了演示,我首先使用Code Interpreter自动生成了5个PDF文件,并将它们压缩成一个包。然后,我上传了文件并输入了上面的提示。

经过一系列步骤,Code Interpreter在每个PDF的每页上添加了水印。

除了为水印指定文本内容之外,您还可以上传一个标志图片或在PDF末尾添加个性签名。
合并和拆分PDF文件 #
将多个相关的PDF文件合并为一个文件可以简化存储和查看。要在上面的示例中合并多个PDF文件,只需输入以下提示。
请合并 将提供的ZIP文件中的所有PDF合并成一个单独的PDF。完成任务后,请提供处理后的PDF的下载链接。
ChatGPT迅速合并了PDF。
此外,使用Code Interpreter拆分PDF也很简单。
从PDF中提取表格和图片 #
从PDF中提取表格可以使数据分析和可视化更加简单。在提取表格之后,我们可以将其转换为Excel文件以进行进一步处理。
为了指示Code Interpreter执行此任务,提示语很简单:
请从PDF中提取表格并将其保存为Excel文件。让我们一步一步来。完成任务后,请提供Excel文件的下载链接。
在我的初次尝试中,它没有起作用,但是添加了短语“让我们一步一步来”后它就起作用了。如果您遇到不稳定的情况 从ChatGPT生成的输出中,您可以尝试添加以下句子:
我想从下面显示的PDF中提取一个表格:
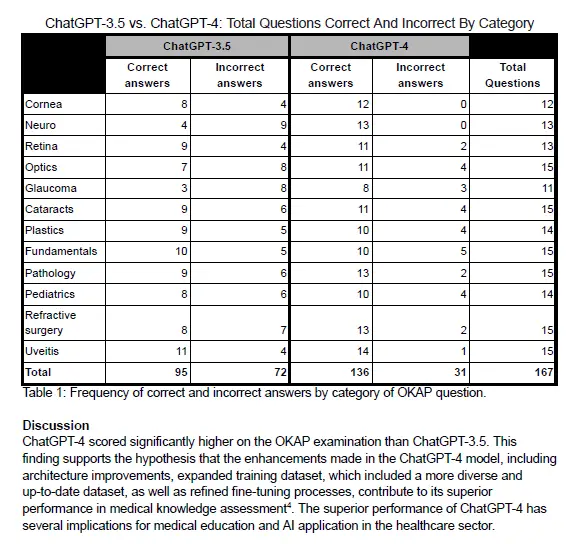
ChatGPT生成的结果表格如下:
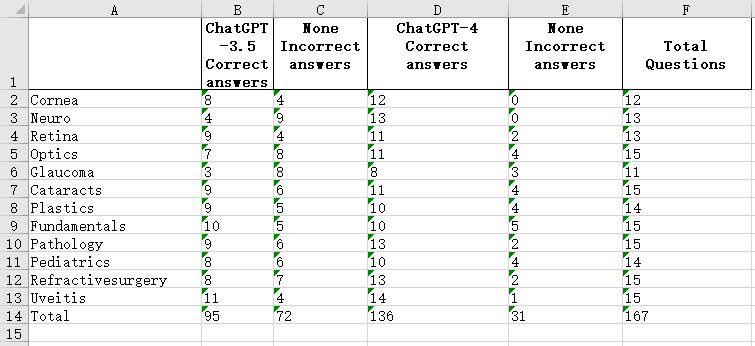
由于原始表格存在合并的单元格,输出表格在行名称上略有不同,但以下数据是正确的。如果您想提取没有合并单元格的原始表格,则结果应与原始表格相同。
在提取表格之后,我们还可以使用代码解释器来分析数据或创建图表。
此外,原始PDF中还有一张条形图的图片。 DF,可以使用哪个代码解释器来帮助提取。
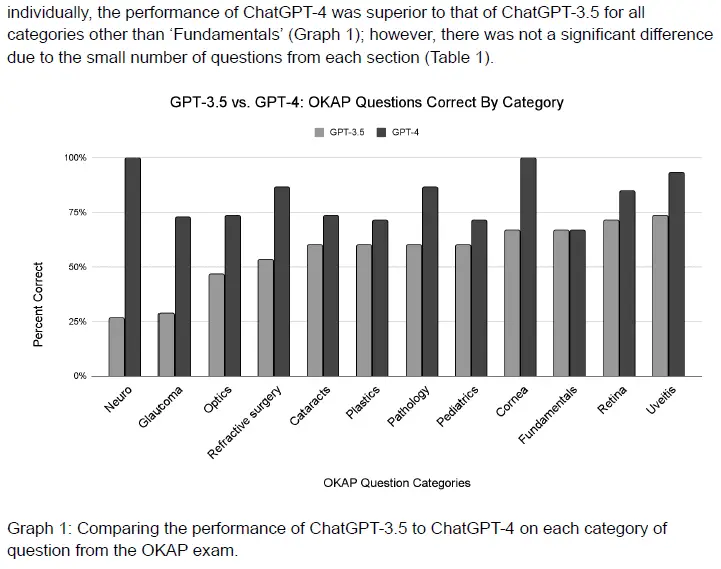
只需向ChatGPT提交以下提示。
请从PDF中提取图像。我们一步一步来。完成任务后,请提供图像的下载链接。
代码解释器成功为我们提取了图像。
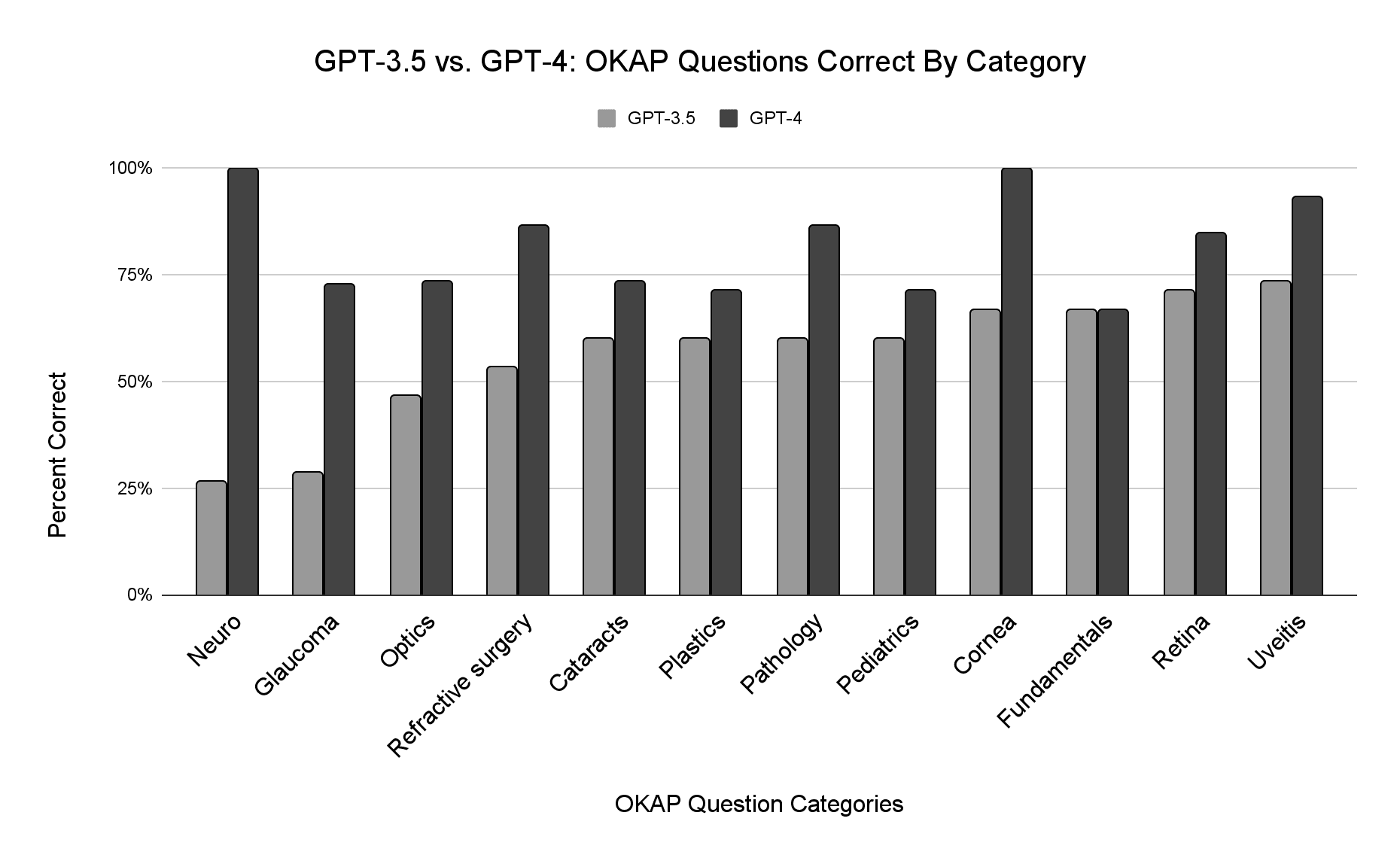
尽管我只使用了一个PDF进行演示,但代码解释器的强大之处在于批量处理。您可以将多个PDF压缩成一个包并上传到ChatGPT进行批量提取。还可以从其他文档格式(如Word文档)中提取表格和图像。
对PDF进行密码保护 #
给PDF添加密码 F确保只有授权的人员可以访问其内容。通过添加密码,您可以保护敏感信息并减少数据泄露的风险。
通过一行提示,可以将密码保护添加到PDF中:
在这个pdf中添加一个密码(yU5NIK5Y)。完成后,请提供下载链接。
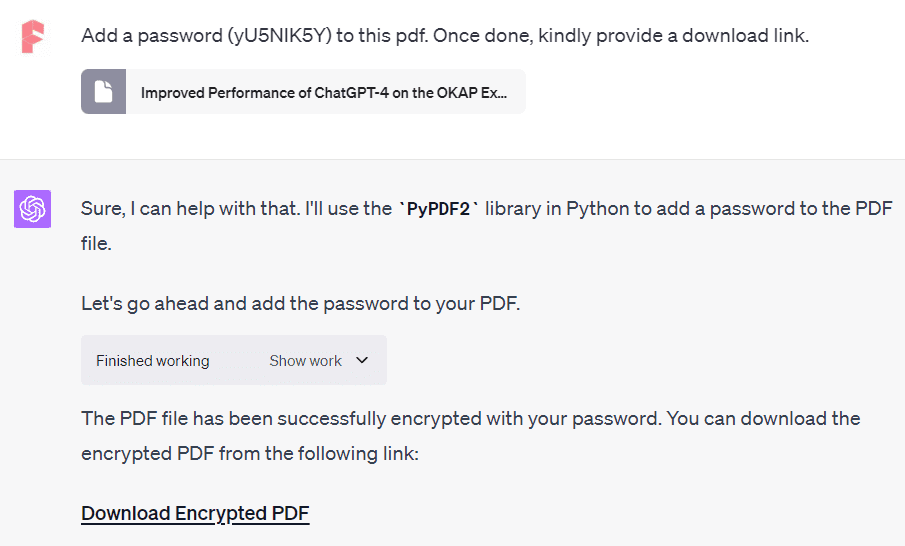
您还可以同时为多个PDF添加密码保护,但请确保记录密码。除了PDF,您还可以加密其他文档类型,如Excel和Word文件。
概括PDF内容 #
有多种方法可以概括PDF内容,其中Code Interpreter是其中之一。Code Interpreter相对于其他方法的一个重要优点是可以批处理处理文档。
您可以压缩多个PDF并上传它们,允许Ch 使用atGPT生成一个摘要的Excel文件,使得访问内容更加方便。
为了演示,我上传了之前提到的PDF,并提交了以下提示。
用三句话总结这个PDF。让我们一步一步来。
让我们来看看ChatGPT的回答,以了解这个过程:
当然,让我先阅读PDF的内容,然后我会提供一个摘要。让我们首先加载并从PDF中提取文本。
...
初始提取的文本中包含了相当多的重复信息,可能是由于PDF中的元数据或页眉页脚导致的。这些重复可能会削弱文档的实际内容。为了得到更准确的摘要,我将尝试通过删除重复的短语来清理这段文本,如果可能的话。让我们继续进行清理,然后进行摘要。
...
文本清理在一定程度上有所帮助,但预览中仍然包含了重复的信息,可能是因为它来自于同一个来源。 没有标题。
... 从PDF中提取正文内容似乎仍然不成功。提取出的文本似乎重复了某些短语,看起来像是页眉或页脚的一部分。
我使用的PyPDF2库用于PDF文本提取,有时可能在复杂的PDF布局或由扫描图像而不是文本创建的PDF上遇到困难。
为了确保最佳结果,我将尝试使用pdfplumber库进行另一种方法,这通常在复杂的PDF上提供更好的结果。
让我们再试一次使用pdfplumber进行文本提取。
...
使用pdfplumber进行提取似乎更成功。文本中似乎没有重复的短语了。 抱歉引起困惑,但当前环境似乎不支持我计划用于文本摘要的transformers库。然而,我仍然可以根据文档的前几行提供一个手动摘要:
- 这篇名为“ChatGPT-4在OKAP考试中的改进表现:与ChatGPT-3.5的比较研究”的文档由马萨诸塞大学医学院眼科学系的团队撰写。
- 这项研究调查了ChatGPT-4这一先进的人工智能(AI)语言模型在眼科学知识评估计划(OKAP)考试中的表现。
- 它将ChatGPT-4与其前身ChatGPT-3.5的表现进行了比较。 使用180个OKAP练习题进行分析时,我们注意到ChatGPT在摘要过程中删除了重复内容,从而得到了更准确的摘要。根据前面部分提供的摘要,它建议我也可以进行更深入的摘要。
为PDF生成词云 #
词云可以将文档中最常用的单词进行压缩和可视化,帮助我们理解PDF中涵盖的关键概念。
为多个PDF生成词云可以揭示文本之间的相似性和差异,有助于比较分析或聚类分析。
为了为PDF生成词云,我使用了以下提示。
请从PDF中删除停用词并生成词云。
![chatgpt代码解释器pdf词云] 但是,代码解释器还可以批量生成多个PDF的词云。它不仅限于PDF,还可以处理其他文档格式,如Word,Markdown,Epub等,以生成词云。
从PDF中提取信息 #
根据先前生成的词云,我们已经知道了PDF中的主要关键词。例如,如果我想提取所有包含词语“model”的句子并将其输出到一个文本文件中,代码解释器可以轻松完成这个任务。
请从PDF中提取包含词语“model”的句子(不区分大小写),并将其保存为一个文本文件。我们一步一步来。任务完成后,请提供文本文件的下载链接。
代码解释器根据我的请求从PDF中提取了句子,将它们导出到一个文本文件中,并提供了一个下载链接。前五个提取的句子如下: ### OCR识别
OCR(光学字符识别)可以将扫描或基于图像的PDF文件转换为可搜索和可选择的文本,使PDF文件更加用户友好并减小文件大小。对于图像,OCR可以将图像中的文本转换为可编辑文本,以便进一步处理。
为了展示Code Interpreter的识别功能,我选择了一封1972年的扫描信件副本。您还可以同时添加多个PDF文件进行识别。

输入以下提示:
请应用OCR技术识别提供的PDF中的文本,并生成一个包含识别文本的新PDF。完成后, 请分享将任务完成后的PDF下载链接。
对于一个包含两页的PDF文件应用OCR识别后,以下是第一页的效果:

结果令人满意,几乎所有的词汇都被正确识别。
批量文件格式转换 #
阅读和处理文档通常需要使用不同的应用程序,每个应用程序支持不同的格式。利用最适合特定目的的格式可以实现对文档的高效处理、共享、保存和利用。代码解释器可以实现不同格式之间的批量转换,使文件在不同系统之间更具多样性。
批量将WebP转换为JPG #
从互联网上下载的许多图片都是WebP图像格式。由于许多图像编辑软件无法识别或支持这种格式, 我们经常需要将WebP图像转换为其他格式,比如JPG。
使用Code Interpreter进行批量转换非常方便。只需将要转换的图像放入一个压缩文件中,上传它,并使用简单的提示指导ChatGPT进行转换过程。
请将压缩包中的所有图片从WebP格式转换为JPG格式。转换完成后,请提供包含处理后图片的压缩包的下载链接。
将网页转换为Markdown #
Markdown是一种纯文本格式,即使没有互联网连接,也可以轻松打开和阅读。将网页转换为Markdown可以更方便地存储。许多笔记应用程序,如Notion,支持导入Markdown内容。
将网页转换为Markdown很简单。首先,将网页保存为MHTML文件,然后将文件上传到Code Interpreter。最后,为ChatGPT编写一个提示,例如:
将此MHTML文件转换为Markdown文件。 提供给我一个下载链接。我们一步一步来。
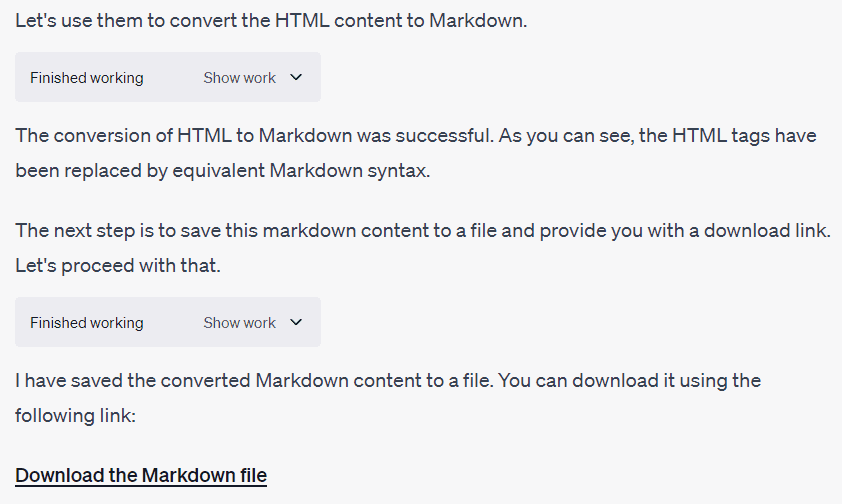
其他格式的转换 #
代码解释器除了上述提到的格式转换之外,还支持许多其他格式的转换。
- 归档: 7Z、TAR、ZIP、RAR、GZ、BZ2、XZ、LZMA
- 音频: MP3、WAV、FLAC、AAC、OGG、M4A、AIFF、WMA、AMR
- 文档: DOC、DOCX、PDF、RTF、HTML、TXT、ODT、EPUB、CSV、XLS、XLSX、PPT、PPTX、Markdown、LaTeX
- 表单: XLSX、CSV
- 图片: PNG、JPG、JPEG、BMP、TIFF、GIF、SVG、ICO、WEBP、RAW、HEIC、EPS、PSD
- 视频: MP4、AVI、MOV、FLV、MKV、WMV、3GP、WebM、MPEG、VOB
- 代码文件: PY、JS、JAVA、C、CPP、CS、R、Swift、PHP、Ruby、Go、Kotlin、Lua、Shell
- 数据文件: JSON、XML、YAML、SQL、HDF5、PICKLE、Parquet、Protobuf
- 字幕: SRT、ASS、SSA、VTT
- 字体: TTF、OTF、WOFF、EOT
- 3D文件: STL,OBJ,FBX,COLLADA,3DS,IGES,STEP
- 地理空间数据: GeoJSON,SHP,KML,GPX,GeoTIFF
- 科学数据格式: FITS,VTK,NetCDF,DICOM
- CAD文件: DWG,DXF
- 电子书籍: EPUB,MOBI,AZW3
- 电子邮件: EML,MSG
- 网络: HTML,CSS,JS,WebAssembly
- 其他: LOG
请注意,尽管代码解释器可以处理这些格式,但在某些情况下,转换它们可能并不容易,甚至不可能。
每个转换取决于使用的特定Python库,文件的复杂性以及格式本身提供的支持。例如,将复杂的DOCX文档转换为HTML可能无法完美地保留格式和布局,因为两种格式之间存在差异。
总结 #
通过代码解释器,文件管理的效率得到了提升。人工智能真正地改变了我们处理文件的方式。
最近,还出现了一个令人兴奋的开源项目,名为Open Interpreter。 它允许您直接在本地计算机上利用代码解释,进一步简化某些工作流程。感兴趣吗?来看看这个:
👉 厌倦了OpenAI的代码解释器限制?请查看GitHub上的Open Interpreter以获得救援 (opens new window)